Empirical Study: Model Compression Applied to VLA

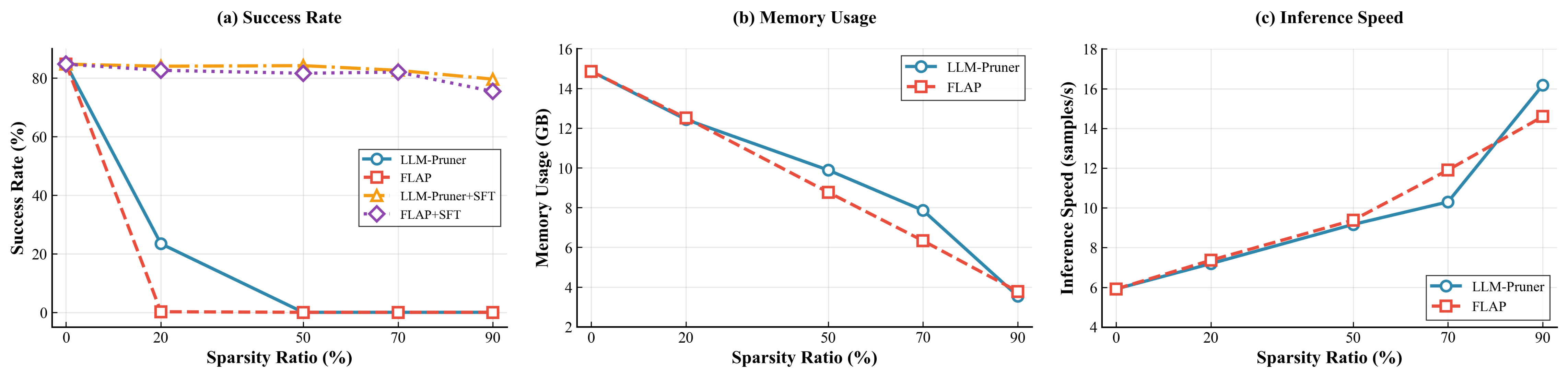
- Quantization has minimal impact on performance, while significantly reducing memory requirements and slightly improving inference speed.
- Unstructured pruning has a smaller impact on performance, whereas structured pruning offers greater acceleration benefits.
- The combination of quantization and pruning can further substantially compress the model.
- The speedup gains from quantization diminish as the sparsity ratio increases.
Method
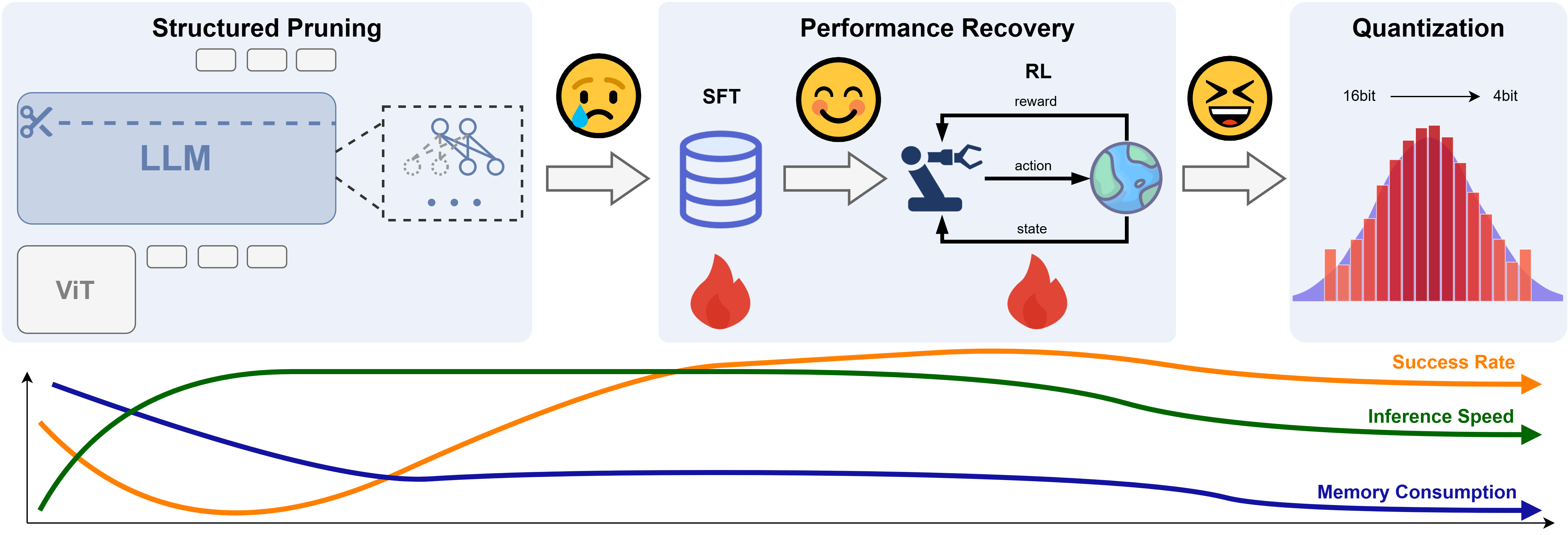
We propose RLRC, a three-stage method: (1) we apply structured pruning to the VLA model, specifically targeting the LLM component, to remove redundant structures in a hardware-friendly manner; (2) we employ a performance recovery stage that combines SFT with RL to restore the model's effectiveness on downstream tasks; (3) we introduce optional quantization to further reduce the memory footprint, enabling efficient deployment on resource-constrained robotic platforms.
Experiments

Main Results. Comparison of task success rates and efficiency metrics.
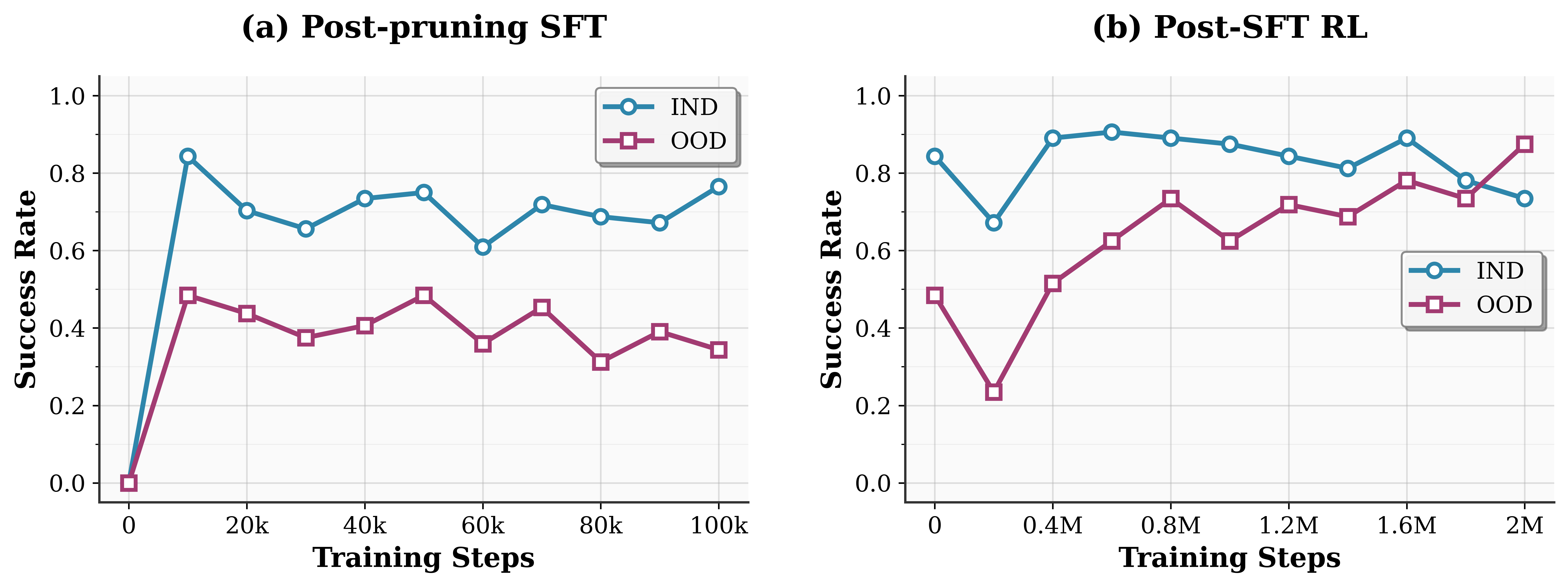
The training curves of SFT and RLFT.
Post-SFT RLFT vs. Scratch RLFT.
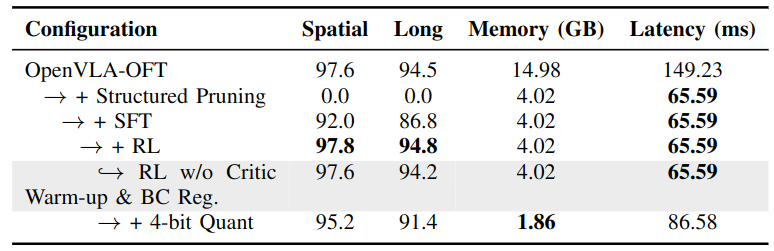
Ablation studies on LIBERO.

Rollout examples from real-world experiments. Video frames are sampled at equal time intervals, with OpenVLA shown on the top and OpenVLA-RLRC on the bottom.
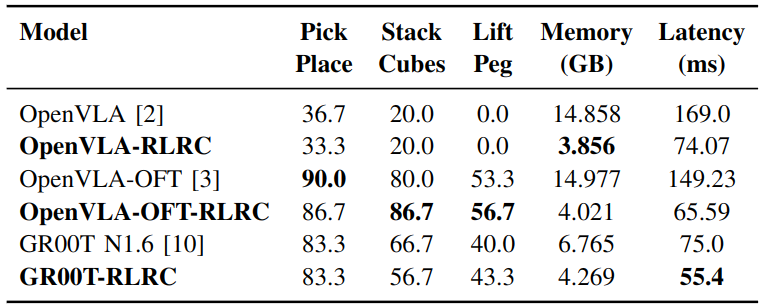
Real-world Results.
- RLRC demonstrates competitive performance compared to other methods.
- Training RLRC incurs extra cost, but its benefits exceed those of training-free acceleration methods and inherently small VLAs.
- RLRC generalizes across diverse architectures, including autoregressive and diffusion-based VLAs, but has structural limitations.
- Each RLRC component plays a complementary role: SFT provides strong initialization for effective RL optimization, while critic warm-up and BC loss regularization stabilize training and improve performance.
- RLRC demonstrates strong performance and effective compression in real-world manipulation tasks.