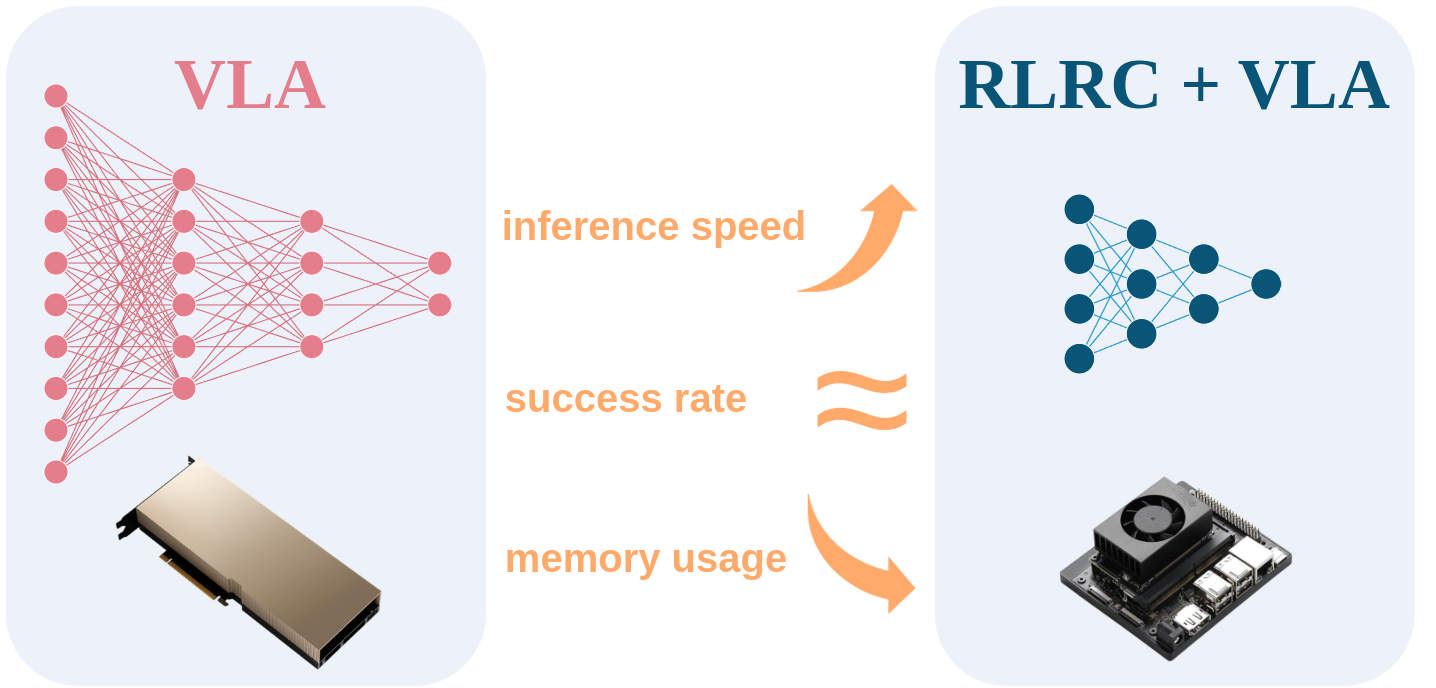
Vision-Language-Action models (VLA) have demonstrated remarkable capabilities and promising potential in solving complex robotic manipulation tasks. However, their substantial parameter sizes and high inference latency pose significant challenges for real-world deployment, particularly on resource-constrained robotic platforms. To address this issue, we begin by conducting an extensive empirical study to explore the effectiveness of model compression techniques when applied to VLAs. Building on the insights gained from these preliminary experiments, we propose RLRC, a three-stage recovery method for compressed VLAs, including structured pruning, performance recovery based on SFT and RL, and further quantization. RLRC achieves up to an 8× reduction in memory usage and a 2.3× improvement in inference throughput, while maintaining or even surpassing the original VLA's task success rate. Extensive experiments show that RLRC consistently outperforms existing compression baselines, demonstrating strong potential for on-device deployment of VLAs.

We propose RLRC, a three-stage method: (1) we apply structured pruning to the VLA model, specifically targeting the LLM component, to remove redundant structures in a hardware-friendly manner; (2) we employ a performance recovery stage that combines SFT with RL to restore the model's effectiveness on downstream tasks; (3) we introduce optional quantization to further reduce the memory footprint, enabling efficient deployment on resource-constrained robotic platforms.
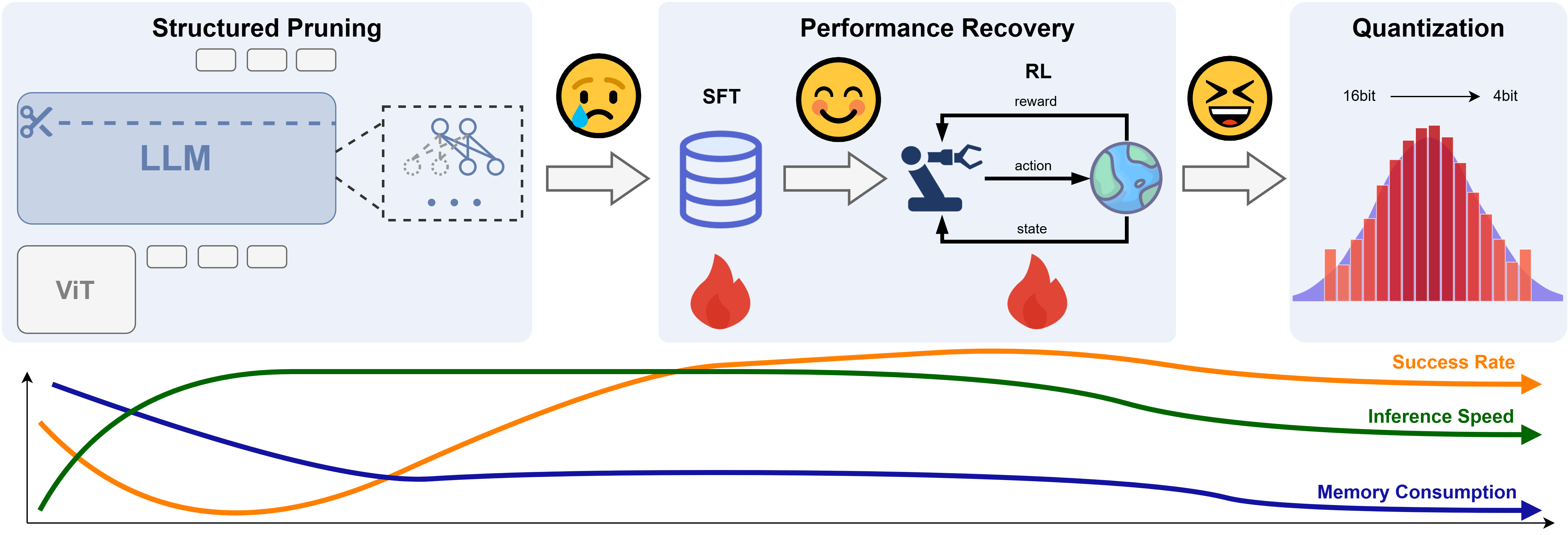
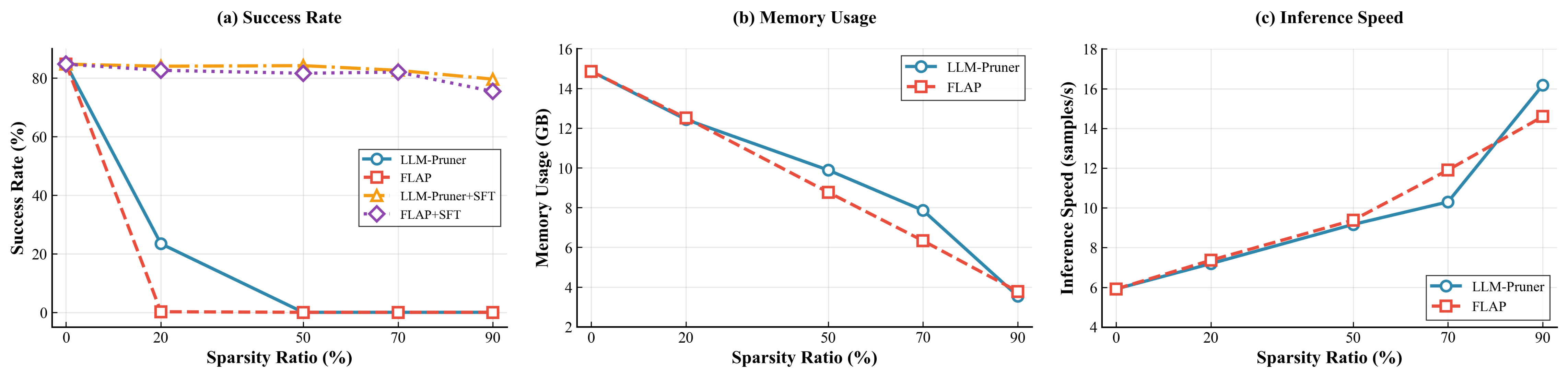
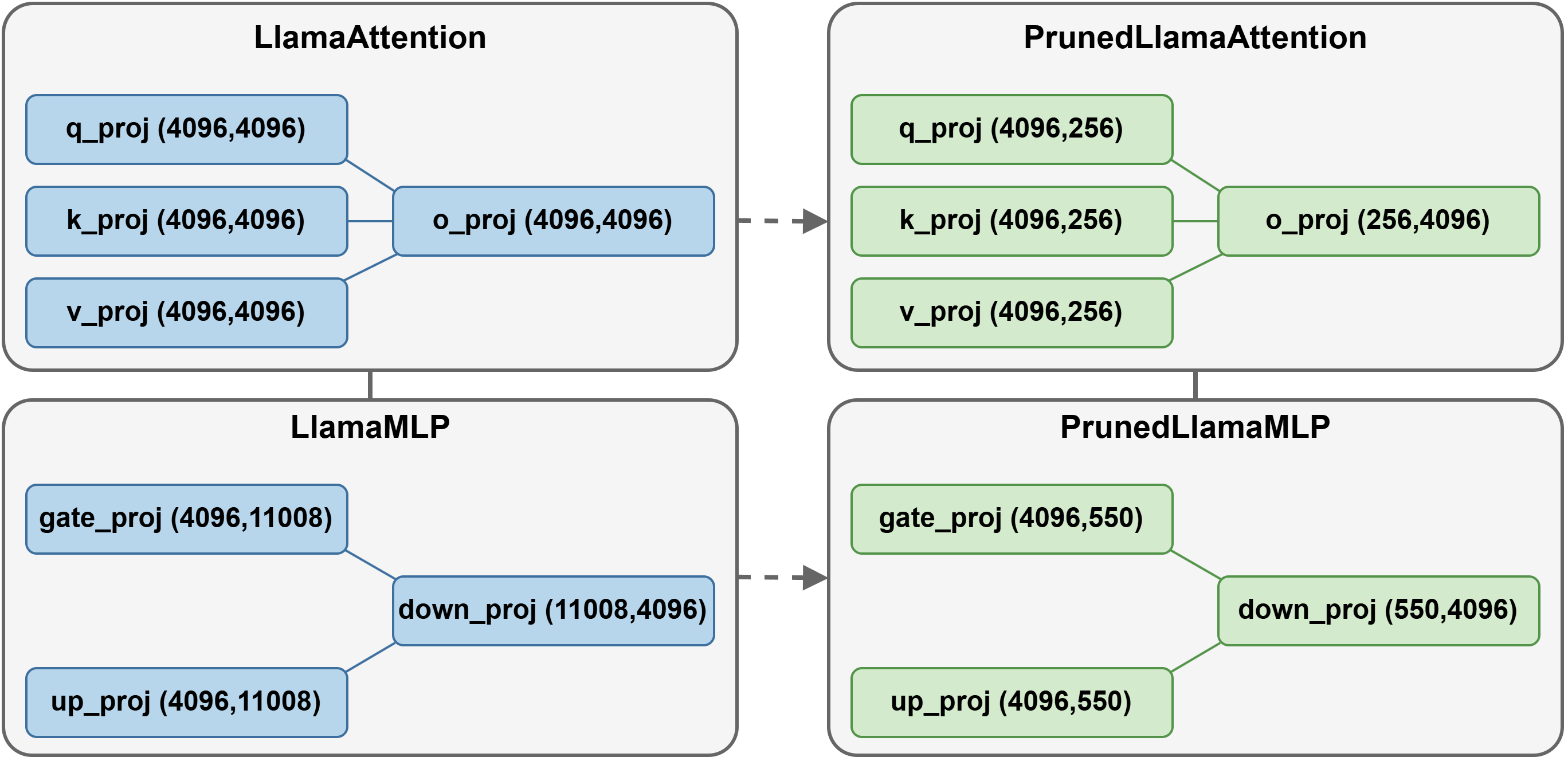
We adopt LLM-Pruner as an off-the-shelf structured pruning framework. Specifically, we apply pruning at the block-wise level and utilize the Taylor importance criterion. To preserve the representational capacity and stability of the model, we retain both the first and last decoder layers, applying pruning only to the intermediate layers. Guided by empirical observations from our earlier experiments, we adopt an aggressive 90\% overall pruning ratio, aiming to substantially reduce the model size.
Compared to unstructured pruning, structured pruning imposes greater performance degradation, especially under high pruning ratios like 90%. To mitigate this, we first apply supervised fine-tuning (SFT) on task-specific data, allowing the pruned VLA model to adapt to its reduced architecture. However, SFT alone cannot fully recover performance, particularly after aggressive 4-bit quantization.
To address this, we incorporate reinforcement learning using Proximal Policy Optimization (PPO), which dynamically adjusts model parameters to recover fine-grained decision-making capabilities. Following Liu et al., we design a shared Transformer backbone for the actor-critic setup, where the critic estimates value from the hidden state of the first action token via a lightweight MLP. Sparse rewards and strong SFT initialization enable efficient and scalable RL fine-tuning (RLFT), enhancing performance in both seen and unseen tasks.
After applying SFT and RL, the pruned VLA achieves task execution performance comparable to, or even surpassing, that of the original VLA. Building upon this strong foundation, we further explore 4-bit quantization to achieve extreme memory compression.

Main Results. Comparison of task success rates and efficiency metrics.
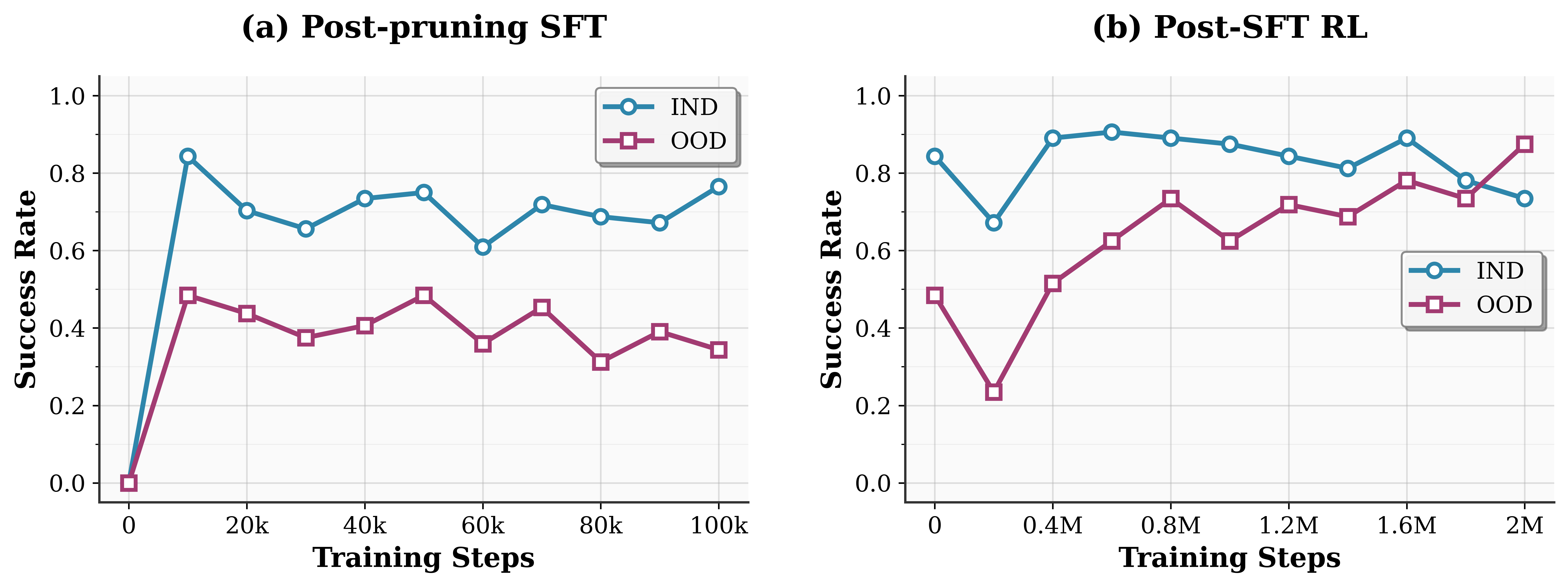
The training curves of SFT and RLFT.
Post-SFT RLFT vs. Scratch RLFT.
@article{chen2025rlrc,
title={RLRC: Reinforcement Learning-based Recovery for Compressed Vision-Language-Action Models},
author={Yuxuan Chen and Xiao Li},
journal={arXiv preprint arXiv:2506.17639},
year={2025}
}